





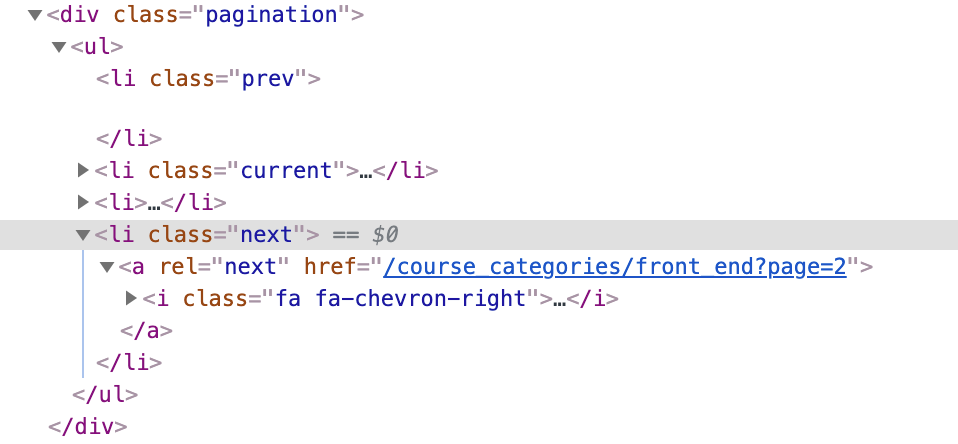
分页
命令行中可以看到 'item_scraped_count': 12,一共爬取到 12 条记录,也就是只爬取了第一页的数据。但是还有第二的数据没有爬取,那要怎么处理才能爬取到所有分页的数据呢?

import scrapy
from ClwySpider.items import ClwyspiderItem
class CourseSpider(scrapy.Spider):
# ...
def parse(self, response):
for course in response.xpath('//div[@id="courseList"]/div/a'):
...